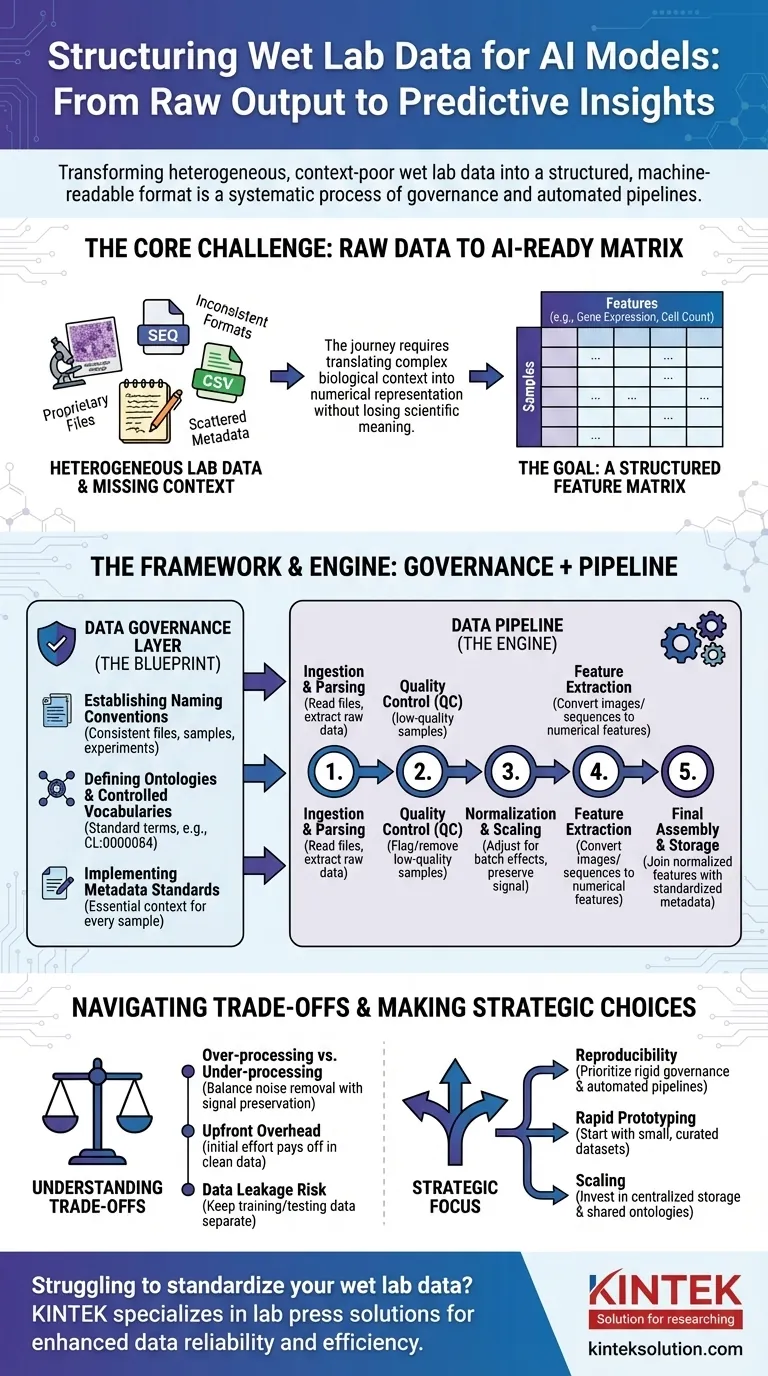
Per preparare i dati di laboratorio umido (wet lab) per l'IA, è necessario trasformarli dal loro stato grezzo, spesso incoerente, in un formato strutturato e leggibile dalla macchina. Questo non è un singolo passaggio, ma un processo sistematico che coinvolge la governance dei dati per creare regole chiare, seguita da pipeline di dati che automatizzano la pulizia, la normalizzazione e la strutturazione degli output sperimentali grezzi in un formato coerente adatto all'addestramento del modello.
La sfida principale non è semplicemente riformattare i file. Si tratta di tradurre sistematicamente il complesso contesto biologico – come le condizioni sperimentali, la storia del campione e le tecniche di misurazione – in una rappresentazione strutturata e numerica da cui un modello di IA possa apprendere senza perdere il significato scientifico critico.

Il Problema Centrale: Dall'Output Grezzo ai Dati Pronti per l'IA
Il viaggio da un banco di laboratorio a un modello predittivo è irto di sfide legate ai dati. L'output grezzo degli strumenti scientifici è raramente, se non mai, pronto per l'uso diretto in un algoritmo di IA.
L'Eterogeneità dei Dati di Laboratorio
I dati di laboratorio umido (wet lab) sono disponibili in una vasta gamma di formati. Ciò include tutto, dai file proprietari di sequenziatori e microscopi ai semplici CSV di lettori di piastre, ognuno con la propria struttura e peculiarità.
Un modello di IA, tuttavia, richiede un formato unificato.
La Maledizione del Contesto Mancante
Informazioni critiche, o metadati, sono spesso disperse. Potrebbero trovarsi nel taccuino di uno scienziato, in un foglio di calcolo separato o semplicemente nella sua mente. Senza questo contesto (ad esempio, quale farmaco è stato applicato, la temperatura, la linea cellulare utilizzata), i dati numerici sono privi di significato.
L'Obiettivo: Una Matrice di Caratteristiche
In definitiva, la maggior parte dei modelli di IA necessita di dati in una matrice di caratteristiche. Questa è una semplice tabella in cui le righe rappresentano i singoli campioni (ad esempio, un paziente, un pozzetto di coltura cellulare) e le colonne rappresentano le caratteristiche (ad esempio, livelli di espressione genica, misurazioni della morfologia cellulare, concentrazioni proteiche).
Un Quadro per la Standardizzazione: Il Livello di Data Governance
Prima di poter costruire pipeline automatizzate, è necessario stabilire delle regole. Questa è la data governance – il progetto che garantisce la coerenza tra tutti gli esperimenti e i team. È il passo più critico e spesso trascurato.
Stabilire Convenzioni di Denominazione
Una regola semplice ma potente è quella di imporre uno schema di denominazione coerente per file, campioni ed esperimenti. Ciò consente di collegare e tracciare i dati in modo programmatico dalla loro origine all'analisi finale.
Definire Ontologie e Vocabolari Controllati
Un'ontologia fornisce un set standard di termini per descrivere le entità biologiche. Ad esempio, invece di consentire "cellula T", "linfocita T" e "Tcellula", un vocabolario controllato impone un singolo termine, come CL:0000084 dall'Ontologia Cellulare.
Ciò previene l'ambiguità e assicura che i dati provenienti da diversi esperimenti siano veramente comparabili.
Implementare Standard di Metadati
È necessario definire i metadati minimi che devono essere catturati per ogni singolo campione. Ciò include spesso la fonte del campione, le condizioni sperimentali, le impostazioni dello strumento e la data. Questa regola garantisce che nessun punto dati diventi un orfano, distaccato dal suo contesto.
Il Motore della Trasformazione: Costruire la Data Pipeline
Con le regole di governance in atto, è possibile costruire una data pipeline. Questa è una serie di passaggi software automatizzati che trasformano i dati grezzi nella matrice di caratteristiche finali pronta per l'IA.
Passo 1: Ingestione e Analisi dei Dati
Il primo compito della pipeline è trovare e leggere i file di dati grezzi. Questo passaggio implica la scrittura di parser specifici per il formato di output di ogni strumento per estrarre le misurazioni primarie e tutti i metadati associati.
Passo 2: Controllo Qualità (QC)
Non tutti i dati sono buoni dati. La pipeline dovrebbe segnalare o rimuovere automaticamente i campioni di bassa qualità basati su metriche predefinite, come un basso numero di cellule in un esperimento di imaging o una scarsa qualità di lettura da un sequenziatore.
Passo 3: Normalizzazione e Scalatura
Le misurazioni provenienti da diversi lotti o piastre spesso presentano variazioni tecniche. La normalizzazione è un passaggio cruciale che adegua i dati per rendere le misurazioni comparabili tra gli esperimenti, rimuovendo il rumore tecnico e preservando il segnale biologico.
Passo 4: Estrazione delle Caratteristiche
I dati grezzi spesso non sono in un formato di caratteristiche. Un'immagine, ad esempio, deve essere elaborata per estrarre caratteristiche numeriche come dimensione, forma e intensità delle cellule. Una sequenza di DNA potrebbe essere convertita in un vettore di frequenza k-mer. Questo passaggio trasforma dati complessi in numeri che l'IA può utilizzare.
Passo 5: Assemblaggio Finale e Archiviazione
Infine, la pipeline unisce le caratteristiche normalizzate con i metadati standardizzati. Questo crea la matrice di caratteristiche finale e pulita, che viene poi salvata in un formato stabile e interrogabile (come Parquet o un database) per l'addestramento del modello.
Comprendere i Compromessi
La strutturazione dei dati non è un processo neutrale. Ogni scelta fatta può influenzare le prestazioni e l'interpretazione finale del modello.
Sovra-elaborazione vs. Sotto-elaborazione
Una normalizzazione o un filtraggio aggressivi possono talvolta rimuovere segnali biologici sottili ma importanti. Al contrario, la mancata rimozione del rumore tecnico garantirà che il modello apprenda dagli artefatti sperimentali invece che dalla biologia. Questo è un equilibrio costante.
La Standardizzazione Crea Costi Iniziali
L'implementazione della data governance richiede un significativo sforzo iniziale e l'adesione dell'intero team. All'inizio può sembrare che rallenti la ricerca, ma ripaga enormemente prevenendo mesi di lavoro di pulizia in seguito.
Il Pericolo della Data Leakage
Una funzione critica della pipeline è quella di mantenere separati i dati di addestramento e di test. Se le informazioni dal set di test (ad esempio, la sua distribuzione complessiva) vengono utilizzate per normalizzare il set di addestramento, le prestazioni del modello saranno artificialmente gonfiate e fallirà nel mondo reale.
Fare la Scelta Giusta per il Tuo Obiettivo
Il tuo approccio alla strutturazione dei dati dovrebbe essere guidato dal tuo obiettivo finale.
- Se il tuo focus principale è la riproducibilità: Dai priorità a una rigida data governance e a pipeline completamente automatizzate e versionate fin dal primo giorno.
- Se il tuo focus principale è la prototipazione rapida: Inizia con un set di dati piccolo e curato manualmente per convalidare il tuo approccio all'IA prima di investire in una pipeline su vasta scala.
- Se il tuo focus principale è l'espansione in una grande organizzazione: Investi massicciamente nell'archiviazione centralizzata dei dati, nelle ontologie condivise e nei componenti comuni della pipeline per prevenire i silos di dati.
In definitiva, trattare i tuoi dati con lo stesso rigore dei tuoi esperimenti di laboratorio umido (wet lab) è la base per costruire un'IA biologica di successo e affidabile.
Tabella Riepilogativa:
| Fase | Azione Chiave | Scopo |
|---|---|---|
| Data Governance | Stabilire convenzioni di denominazione, ontologie, standard di metadati | Garantire coerenza e comparabilità tra gli esperimenti |
| Data Pipeline | Ingestire, analizzare, eseguire QC, normalizzare, estrarre caratteristiche, assemblare | Automatizzare la trasformazione dei dati grezzi in una matrice di caratteristiche pronta per l'IA |
| Compromessi | Bilanciare sovra-elaborazione vs. sotto-elaborazione, gestire i costi iniziali | Ottimizzare le prestazioni del modello ed evitare la data leakage |
Hai difficoltà a standardizzare i tuoi dati di laboratorio umido (wet lab) per l'IA? KINTEK è specializzata in presse da laboratorio, comprese presse da laboratorio automatiche, presse isostatiche e presse da laboratorio riscaldate, al servizio dei laboratori per migliorare l'affidabilità dei dati e l'efficienza sperimentale. Lascia che ti aiutiamo a ottenere risultati coerenti — contattaci oggi per discutere le tue esigenze e scoprire come le nostre soluzioni possono supportare la tua ricerca basata sull'IA!
Guida Visiva