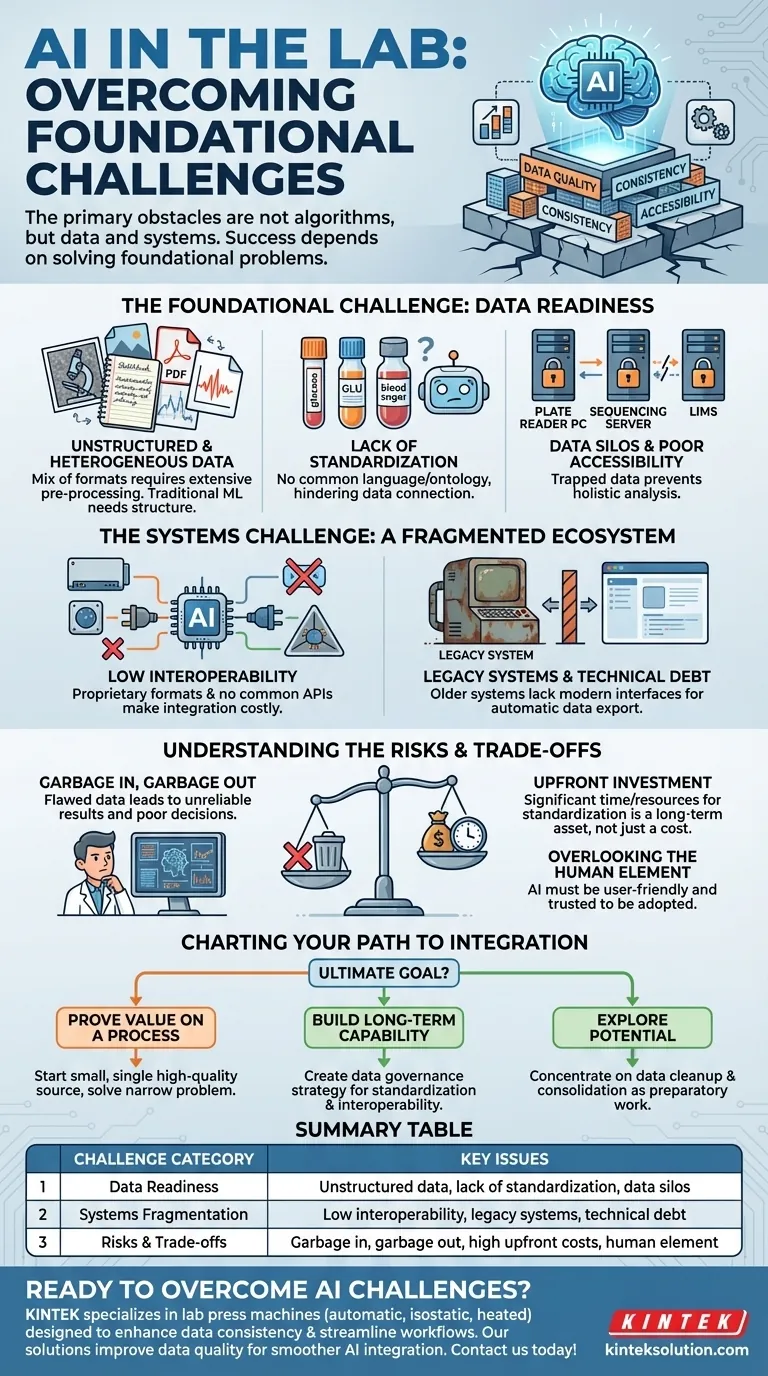
Gli ostacoli principali all'integrazione dell'IA non risiedono negli algoritmi stessi, ma nei dati e nei sistemi fondamentali del laboratorio. Le sfide più significative riguardano la gestione di enormi quantità di dati non strutturati, una diffusa mancanza di standardizzazione dei dati e la bassa interoperabilità tra i diversi strumenti e sistemi software di laboratorio.
Il successo di qualsiasi iniziativa di IA in laboratorio è determinato prima che il primo algoritmo venga eseguito. Dipende quasi interamente dalla risoluzione dei problemi fondamentali di qualità, coerenza e accessibilità dei dati.

La sfida fondamentale: la preparazione dei dati
Prima che l'IA possa fornire approfondimenti, ha bisogno di dati puliti, organizzati e comprensibili. Sfortunatamente, l'ambiente di laboratorio tipico è spesso l'opposto. Questo divario nella preparazione dei dati è l'ostacolo più grande.
Dati non strutturati ed eterogenei
La maggior parte dei dati di laboratorio non è in un formato semplice e tabellare. Esiste come immagini da microscopi, testo in quaderni di laboratorio, PDF di letture strumentali e file di segnale grezzi da vari dispositivi.
I modelli di IA, in particolare l'apprendimento automatico tradizionale, richiedono dati strutturati per funzionare efficacemente. Alimentarli con questo mix di formati senza un'ampia pre-elaborazione è una ricetta per il fallimento.
Mancanza di standardizzazione
Spesso non esiste uno standard unico e imposto per come i dati vengono nominati, formattati o registrati. Uno strumento potrebbe etichettare un campione "glucosio", un altro "GLU" e un registro manuale potrebbe chiamarlo "zucchero nel sangue".
Senza un linguaggio comune, o ontologia, un'IA non può collegare in modo affidabile punti dati correlati tra diversi esperimenti o sistemi. Questa incoerenza mina fondamentalmente la sua capacità di vedere un quadro completo.
Silos di dati e scarsa accessibilità
I dati sono frequentemente intrappolati in sistemi isolati. L'output di un lettore di piastre potrebbe risiedere sul suo PC dedicato, mentre i dati di sequenziamento risiedono su un server separato e i metadati dei campioni sono bloccati in un LIMS (Laboratory Information Management System).
Questi "silos di dati" impediscono all'IA di accedere e correlare le informazioni da diverse fonti, il che è fondamentale per scoprire schemi complessi.
La sfida dei sistemi: un ecosistema frammentato
L'hardware e il software che generano dati di laboratorio sono raramente progettati per funzionare insieme. Questa frammentazione crea un'enorme attrito tecnico per qualsiasi progetto di integrazione dell'IA.
Bassa interoperabilità
Strumenti diversi, spesso di fornitori concorrenti, utilizzano software proprietari e formati di dati che non comunicano tra loro. L'estrazione dei dati richiede spesso l'esportazione manuale, script personalizzati o talvolta è impossibile.
Questa mancanza di un protocollo di comunicazione comune (come un'API) significa che ogni nuova connessione tra un sistema e la tua piattaforma AI diventa un progetto di integrazione personalizzato e costoso.
Sistemi legacy e debito tecnico
Molti laboratori si affidano a strumenti o software più datati che sono stati affidabili per anni. Questi sistemi legacy non sono mai stati progettati per il mondo interconnesso e incentrato sui dati che l'IA richiede.
Spesso mancano delle interfacce moderne necessarie per esportare automaticamente i dati, creando una barriera significativa. Sostituirli è costoso, ma aggirarli è complesso e fragile.
Comprendere i compromessi e i rischi
Ignorare queste sfide fondamentali e procedere con un progetto di IA introduce rischi significativi ed è la causa più comune di fallimento.
Il rischio di "Garbage In, Garbage Out" (spazzatura in ingresso, spazzatura in uscita)
Questa è la regola cardinale della scienza dei dati. Un modello di IA addestrato su dati inconsistenti, disordinati o errati produrrà risultati inaffidabili e fuorvianti.
Peggio ancora, può creare un falso senso di fiducia, portando a decisioni scientifiche o aziendali sbagliate basate su previsioni di IA errate. Il modello non è il problema; i dati lo sono.
Il costo dell'investimento iniziale
Affrontare correttamente la standardizzazione dei dati e l'interoperabilità dei sistemi richiede un significativo investimento iniziale di tempo, risorse e personale. Non esistono scorciatoie.
Tuttavia, questo investimento non dovrebbe essere visto come un costo dell'IA, ma come un bene a lungo termine. Un'infrastruttura dati pulita e accessibile beneficia ogni aspetto del laboratorio, non solo un singolo progetto di IA.
Trascurare l'elemento umano
Uno strumento di IA è efficace solo se viene utilizzato. Se il sistema è difficile da interagire, non si integra nei flussi di lavoro esistenti o produce risultati di cui gli scienziati non si fidano, verrà abbandonato.
Un'integrazione di successo richiede di concentrarsi sull'esperienza dell'utente finale, assicurando che l'IA fornisca risultati chiari e spiegabili che aumentino, piuttosto che interrompano, il lavoro dello scienziato.
Tracciare il tuo percorso verso l'integrazione dell'IA
La tua strategia per implementare l'IA dovrebbe essere dettata dal tuo obiettivo finale. Il primo passo giusto dipende dalla portata della tua ambizione.
- Se il tuo obiettivo principale è dimostrare il valore su un processo specifico: Inizia in piccolo con una singola fonte di dati di alta qualità e risolvi un problema ristretto e ben definito.
- Se il tuo obiettivo principale è costruire una capacità di IA a lungo termine, a livello di laboratorio: Il tuo primo progetto deve essere la creazione di una strategia di governance dei dati che affronti la standardizzazione e l'interoperabilità frontalmente.
- Se il tuo obiettivo principale è semplicemente esplorare il potenziale dell'IA: Concentrati sulla pulizia e il consolidamento dei dati, poiché questo è il lavoro preparatorio più prezioso e necessario per qualsiasi futura iniziativa di IA.
In definitiva, preparare il tuo laboratorio per l'IA significa costruire una solida base di dati puliti, connessi e accessibili.
Tabella riassuntiva:
| Categoria della sfida | Problemi chiave |
|---|---|
| Pronto all'uso dei dati | Dati non strutturati, mancanza di standardizzazione, silos di dati |
| Frammentazione dei sistemi | Bassa interoperabilità, sistemi legacy, debito tecnico |
| Rischi e compromessi | Garbage in, garbage out, costi iniziali elevati, elemento umano |
Pronto a superare le sfide di integrazione dell'IA nel tuo laboratorio? KINTEK è specializzata in presse da laboratorio, comprese presse da laboratorio automatiche, presse isostatiche e presse da laboratorio riscaldate, progettate per migliorare la coerenza dei dati e ottimizzare i flussi di lavoro per i laboratori. Le nostre soluzioni aiutano a migliorare la qualità dei dati e l'interoperabilità del sistema, rendendo l'integrazione dell'IA più fluida ed efficace. Contattaci oggi per scoprire come possiamo supportare le esigenze del tuo laboratorio e promuovere l'innovazione!
Guida Visiva